
Morfologia delle trascrizioni, parte II: codificare il tempo
ShareTIGR
9 May 2024
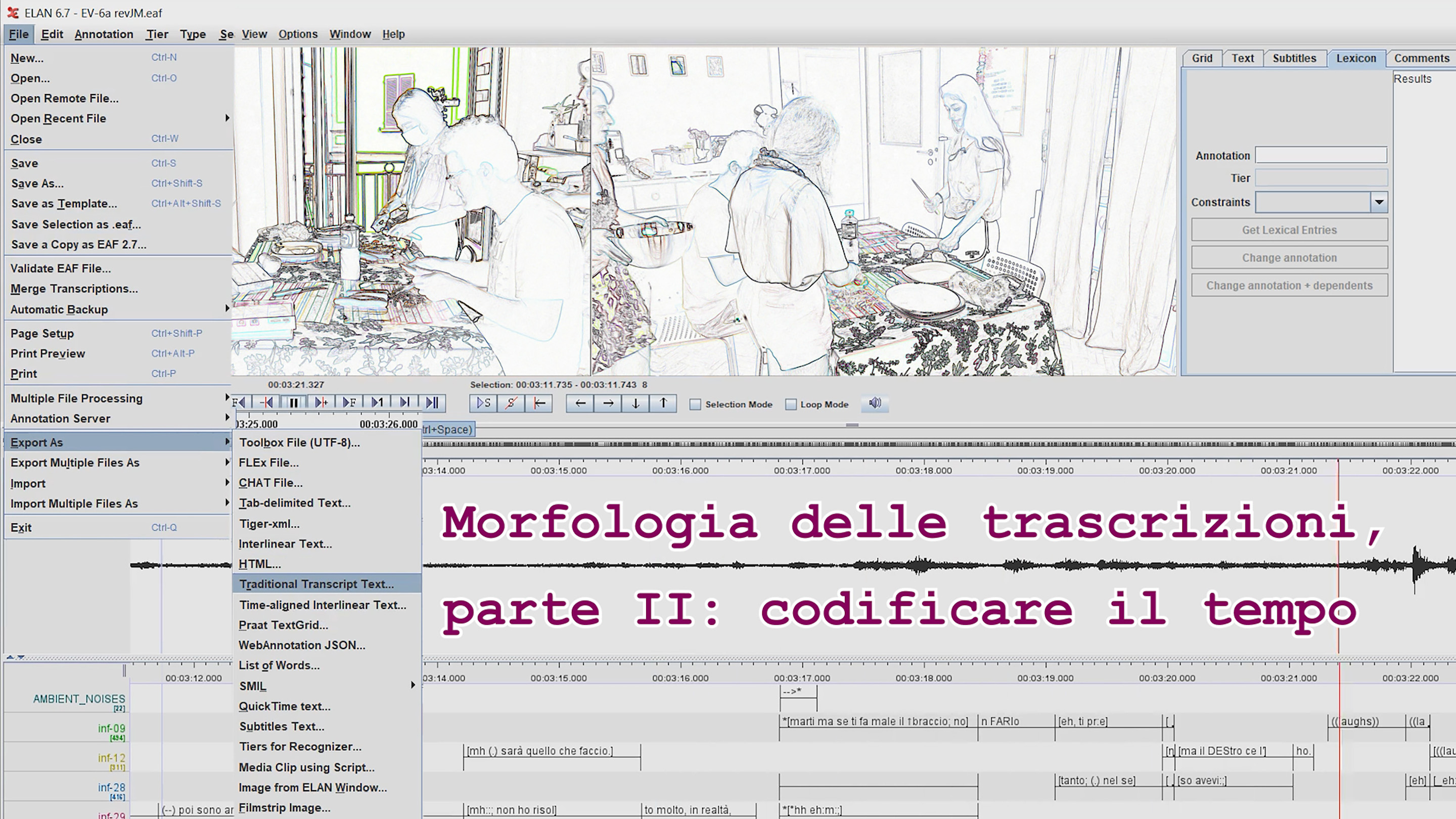
La settimana scorsa ho annunciato di voler dedicare alcuni contributi alla conversione delle trascrizioni effettuate in ELAN in trascrizioni in formato testo (txt), impaginate secondo convenzioni diffuse nel campo dell'analisi della conversazione. Si tratta di una conversione non solo tecnica, ma che interessa la struttura dei documenti a un certo livello di profondità. Per ottenere i risultati desiderati, è perciò utile soffermarsi su alcune differenze tra i due tipi di documento. Nel presente contributo e nell'associato video metto a fuoco, in particolare, un tipo di informazione che le trascrizioni prodotte da annotatori multimediali (come ELAN) contengono e che invece di solito è assente dalle trascrizioni tradizionali, vale a dire il timecode. Discuto il ruolo del timecode, le opzioni di esportazione che ELAN offre al riguardo e come abbiamo deciso di trattare il timecode in ShareTIGR. La prossima settimana spiegherò più in dettaglio la soluzione tecnica che abbiamo adottato.
Da quando si usa il timecode in linguistica e nelle ricerche sull'interazione? Fino alla diffusione dei formati digitali per rappresentare documenti sonori e audiovisivi, la trascrizione di una conversazione audio- o videoregistrata consisteva nella produzione di un testo dattiloscritto o scritto al computer che non conteneva rimandi a luoghi precisi nelle registrazioni ascoltate. Il testo era fruibile in parallelo con la registrazione, grazie all'uso contemporaneo di due macchine diverse, per esempio un magnetofono e un computer. Chi sincronizzava le macchine era la persona che leggeva e ascoltava, senza possibilità di comunicazione diretta tra le macchine. La situazione cambiò appunto con l'arrivo dei formati audiovisivi digitali. Divenne possibile consultare tutti i documenti relativi a una registrazione in un unico ambiente integrato e usare applicazioni per stabilire rapporti fra essi. È in quel tipo di ambiente digitale che si cominciò a usare una informazione che fino ad allora non aveva avuto particolare importanza nel lavoro sul linguaggio e la conversazione: il timecode.
Il timecode è una sequenza di numeri generati a intervalli regolari, che viene associata alla traccia sonora di un'audioregistrazione e alla sequenza di immagini di un filmato video. Nell'industria cinematografica, sin dalla sua invenzione negli anni 1960, la funzione principale del timecode è stata quella di facilitare il montaggio dei nastri video. Infatti, se i generatori di timecode di tutti i registratori (audio e video) sono ben calibrati durante le riprese, i codici permettono di reperire facilmente posizioni corrispondenti nelle tracce di una produzione, così da intervenire in vari modi, per esempio facendo dei tagli.
Quando invece si trascrive una conversazione in un ambiente digitale multimediale, la funzione principale del timecode è quella di definire momenti in un documento audio (eventualmente sincronizzato con ulteriori documenti audio e/o video) da far corrispondere a luoghi nel testo trascritto. Un programma di trascrizione è un annotatore di documenti multimedia che combina funzioni di riproduzione audio/video con un editor dove inserire annotazioni e, inoltre, degli strumenti di ricerca per interrogare il testo inserito. Ogni annotazione ha un inizio e una fine, indicati dai numeri del timecode. Durante il processo di trascrizione, uno dei principali vantaggi di questa procedura è la precisione: una volta fatta l’associazione tra una porzione di testo trascritto e l’audio/video, si può riascoltare facilmente la registrazione per verificare la correttezza di quella esatta porzione di testo. Nella visualizzazione a schermo, l'allineamento temporale ha particolare rilevanza in annotatori come ELAN, che organizzano il testo come una serie di tracce parallele, per esempio una per parlante; saranno allineate verticalmente le annotazioni in tracce diverse che corrispondono allo stesso lasso di tempo. Nella lettura e interrogazione di una trascrizione, il vantaggio dell'allineamento temporale è che si può navigare fra i vari documenti con grande facilità, passando in modo automatico da qualsiasi luogo del testo al luogo corrispondente nei documenti audio/video e vice versa. In questo modo si sfrutta appieno, ai fini della ricerca sul parlato, il potenziale di un ambiente digitale multimediale.
Proprio quest'ultima funzione, la navigazione, è presente anche nelle piattaforme di interrogazione dei corpora orali - ancora grazie al timecode, che è conservato nelle trascrizioni annotate, o trasformate in banche dati, che si usano in quelle piattaforme. Ma che cosa succede quando si converte il documento originale in una trascrizione impaginata in modo tradizionale? È possibile mantenere il timecode? È auspicabile, in vista dell'uso futuro della trascrizione?
Partendo dal caso del TIGR trascritto in ELAN, conviene prima di tutto constatare che questo programma, quando si esportano le trascrizioni in formato testo, offre due opzioni: o si esportano tutte le indicazioni temporali o nessuna. La prima opzione permette di mantenere un massimo di informazione. Ma il risultato convince poco: si alternano, riga per riga, segmenti trascritti e numeri di timecode e, poiché i segmenti per vari motivi sono in media brevi, la quantità di cifre supera decisamente quella delle lettere. Un eccesso di informazione temporale, dunque, che compromette la leggibilità del documento! Inversamente, quando si sceglie di omettere il timecode, si ottiene un documento tradizionale a tutti gli effetti, senza numeri fastidiosi, ma anche privo di qualsiasi ausilio al passaggio fra testo trascritto e documenti audio/video.
Come menzionato nel contributo della scorsa settimana, il team di InfinIta ha realizzato alcuni compiti nel programma di annotazione INCEpTION in una fase precoce del progetto. In quel periodo, usavamo versioni TXT delle trascrizioni esportate da ELAN senza timecode. Questa scelta ci permetteva di raggiungere i nostri scopi, ma l'assenza di indicazioni temporali era un ostacolo quando si trattava di ritrovare, nei documenti audio/video, la posizione corrispondente a un determinato luogo nella trascrizione. Eravamo lenti a navigare tra i documenti e sarebbe stato molto utile disporre di almeno alcuni punti di riferimento. Non era possibile, forse, ridurre le tante indicazioni temporali contenute nel documento originale alle poche che servivano per orientarsi? Non sarebbe stata, quella, una soluzione utile, non solo per noi, ma anche per chi avrebbe usato versioni TXT delle nostre trascrizioni in futuro?
Proprio in questa direzione stiamo ora andando in ShareTIGR, grazie a uno script in Python che, operando su documenti TXT esportati con le indicazioni temporali, ne elimina gran parte per lasciarne solo a certi intervalli, definiti dall'utente. Lo script produce un documento intermedio che in seguito è elaborato ulteriormente per risolvere diversi problemi di organizzazione e impaginazione del testo. Scegliendo un intervallo di alcuni secondi - in ShareTIGR abbiamo optato per 10 secondi - si ottiene una trascrizione tradizionale ottimizzata per il lavoro con file audio/video al di fuori di un ambiente multimediale integrato. Nei prossimi contributi descriverò lo script che tratta il timecode e quelli successivi, riflettendo anche sul ruolo della programmazione informatica fra gli arnesi del/la linguista.
Johanna Miecznikowski
