
Morfologia delle trascrizioni, parte VI: uso di script in fase di impaginazione e di revisione
ShareTIGR
11 July 2024
Nel contributo video Morfologia delle trascrizioni V abbiamo mostrato alcune operazioni da fare manualmente quando si impaginano le trascrizioni in formato testo dopo la loro esportazione da ELAN. Per aumentare la precisione e ridurre il tempo che ci vuole per completare questa fase di elaborazione, abbiamo però deciso di non fare proprio tutto a mano. Piuttosto, poiché si era già rivelato utile il ricorso a Python per intervenire sulle indicazioni temporali, abbiamo deciso di predisporre alcuni ulteriori script funzionali all’impaginazione. È così nato un piccolo pacchetto di script che abbiamo chiamato TIGRlayout.
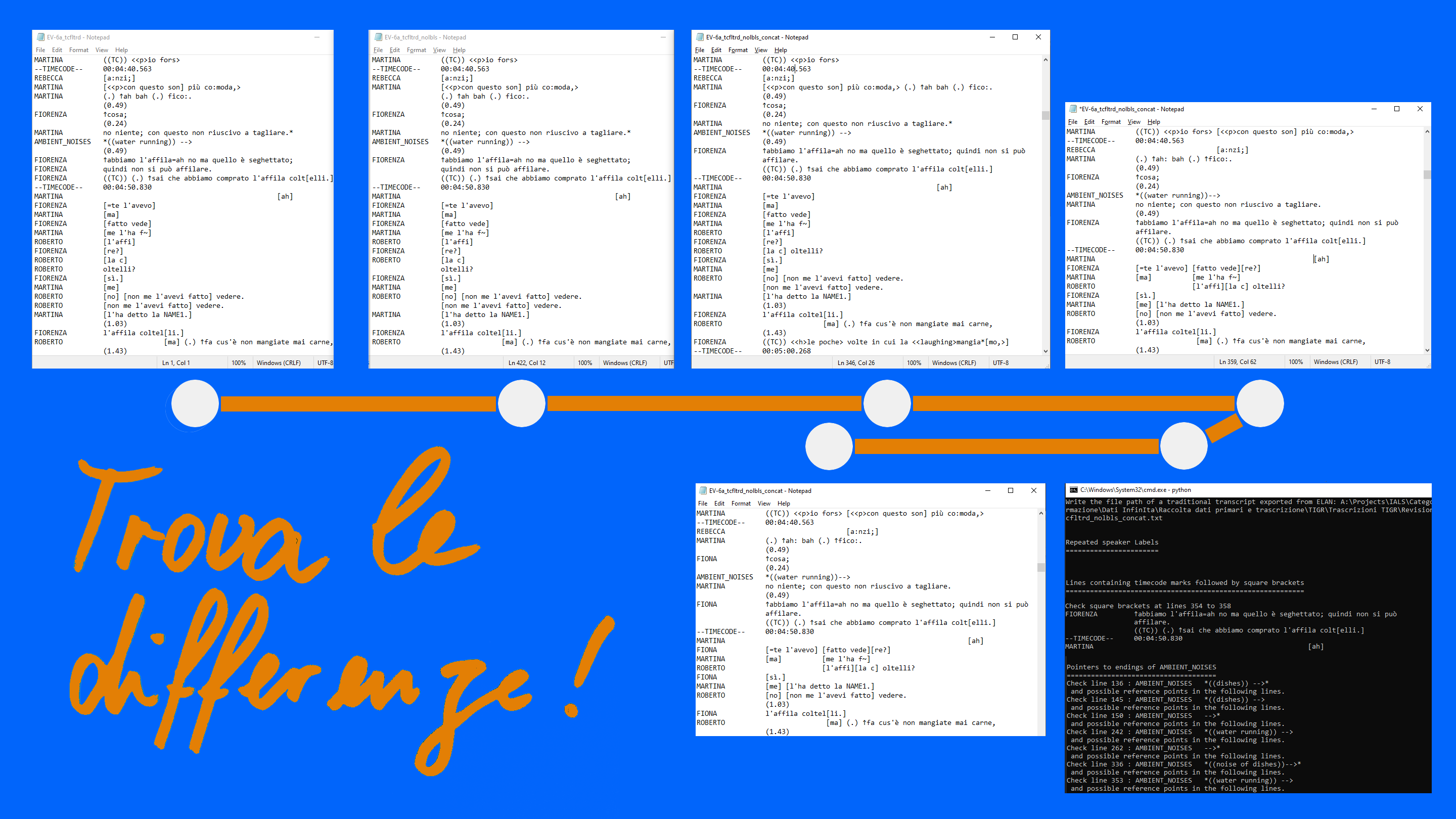
Il primo programma del pacchetto dev’essere applicato in realtà ancora prima dell’intervento sul timecode e mira a trovare un particolare tipo di errore che capita di fare trascrivendo in ELAN, e cioè l’omissione di una parentesi quadra. Ricordiamo che le parentesi quadre in una trascrizione sono usate per segnalare l’inizio e la fine di una sovrapposizione tra parlanti. Esse sono fondamentali per l’impaginazione perché segnalano luoghi, nei discorsi di parlanti diversi, che dovranno essere allineati verticalmente. Quando manca una parentesi quadra di apertura o di chiusura, ne risultano incoerenze logiche e allineamenti verticali sbagliati.
Come allora trovare le parentesi quadre mancanti? Il programma legge prima di tutto il testo, interpretandolo come una semplice stringa di caratteri. In seguito trova tutte le parentesi quadre di apertura (“[“), le inserisce in un particolare tipo di lista e percorre uno a uno gli elementi della lista, cercando ogni volta la prossima istanza di una parentesi quadra nel cotesto successivo. Quando quell’istanza è una parentesi di chiusura, passa al prossimo elemento della lista. Quando invece trova un’altra parentesi di apertura, produce un messaggio per l’utente che gli permetterà di ritrovare e correggere l’errore a mano: mostra un messaggio del tipo “in questa riga manca una parentesi di chiusura”, riproduce il contenuto della riga problematica e aggiunge il numero di riga. Arrivato alla fine della lista contenente le parentesi di apertura, il programma ripete l’intera operazione per le parentesi quadre di chiusura (“]”), guardando stavolta il cotesto precedente per capire se la parentesi di chiusura è preceduta da una di apertura o meno. Terminata questa seconda verifica, segnala all’utente che tutte le parentesi sono state verificate. Spetta all’utente confrontare i passi problematici con il documento aperto in ELAN e correggere gli errori nei due documenti, sia EAF, sia TXT.
Il secondo programma del pacchetto serve a compiere un intervento che ELAN sa fare da solo, ma che abbiamo saltato per poter filtrare il timecode: eliminare certe etichette dei/delle parlanti. Nella versione del testo che abbiamo usato per filtrare il timecode, all’inizio di ogni riga è indicato il nome – l’etichetta o label – del/la parlante che pronuncia il contenuto di quella riga. Quando però il/la parlante non cambia, questa indicazione è inutile, e anzi reca disturbo. Conviene perciò eliminare quelle etichette superflue. Lo script affronta il problema interpretando il testo come elenco di righe. Percorre le righe e quando ne incontra una che inizia con una lettera – indizio sicuro della presenza di un nome di parlante – identifica e memorizza l’etichetta del/la parlante e inizia una verifica nel cotesto successivo. Sostituisce con una serie di spazi eventuali etichette identiche nelle righe immediatamente adiacenti, ignorando le righe che contengono timecode o pause. Quando incontra un’etichetta diversa, cioè quando cambia il/la parlante, il programma comincia da capo il processo di verifica e sostituzione ripartendo da quella. Arrivato all’ultima riga del testo, salva la versione modificata aggiungendo “nlbls” (per no labels) al nome del documento.
Il terzo programma del pacchetto mira a concatenare i segmenti pronunciati dallo/a stesso/a parlante per formare quello che potremmo chiamare l’approssimazione di un turno di parola.
Inserisco a questo punto una parentesi teorica e di metodo. Nella conversazione informale, spesso i/le partecipanti competono per ottenere il diritto alla parola (o, al contrario, avere il diritto di rimanere in silenzio...) e solo raramente il risultato è una sequenza in cui per ogni momento del discorso si possa determinare in modo univoco di chi è il turno. Un turno di parola è il prodotto dell’interpretazione congiunta di più persone e i suoi confini sono spesso reinterpretate nel corso dell’interazione. Fissare questi confini in una trascrizione è un’impresa un poco arbitraria e, infatti, una trascrizione a spartito come quella prodotta in ELAN rinuncia interamente alla delimitazione di unità che assomigliano ai turni. In una trascrizione in formato testo come la nostra, la cui forma ideale è il copione teatrale, se vogliamo, è invece inevitabile creare difatti delle “battute” o appunto approssimazioni di turni, che corrispondono alle fasi della conversazione in cui parla una persona alla volta. Nel TIGR, abbiamo deciso di rappresentare graficamente come unità di questo genere tutti i segmenti prodotti in sequenza da un/a parlante che non sono separati dall’intervento verbale di qualcun altro. Quelle unità comprenderanno anche tutti i silenzi non seguiti da un cambiamento di parlante, indipendentemente dalla loro durata, senza pretesa di “attribuire” i silenzi al/la parlante che parla prima o dopo. Per convenzione, poi, abbiamo deciso di collocare su una riga a se stante l’ultimo silenzio che precede il cambiamento di parlante.
Concretamente, come anticipato nel video della scorsa settimana, per ottenere questo genere di struttura occorre concatenare i segmenti e le pause in questione, eliminando gli a capo inseriti da ELAN dopo ogni segmento, e reinserire degli a capo nuovi per ottenere un’impaginazione regolare e compatta. Il terzo script del pacchetto TIGRlayout esegue in modo automatico parte di questi lavori di impaginazione. Come quello presentato poco fa, legge il testo interpretandolo come un elenco di righe. In una prima tappa, concatena tutte le righe che seguono un’etichetta di un/a parlante fino ad incontrare la prossima etichetta o un’indicazione di timecode. In una seconda tappa, ripete questa operazione per le righe che segono un’indicazione di timecode. Nei due casi, ignora le righe che contengono parentesi quadre e dunque discorsi in sovrapposizione, che devono essere trattati manualmente, e mantiene su una riga separata le pause che precedono un cambiamento di parlante. Procedere in due tappe come appena descritto è un metodo semplice per non concatenare le indicazioni di timecode stesse, che per una migliore visibilità devono mantenere la loro autonomia come righe a se stanti. Una volta concatenati i segmenti, bisogna introdurre degli a capo, nel nostro caso in tal modo da non superare una lunghezza di riga massima di 86 caratteri. Questo numero corrisponde al numero massimo di caratteri per riga che abbiamo scelto durante l’esportazione da ELAN – pari a 80 caratteri – più altri sei caratteri che corrispondono alla lunghezza del riferimento “((TC))” (per timecode), riferimento che il primo script descritto su questo blog aveva aggiunto a intervalli di circa 10 secondi. Lo script percorre il testo riga per riga. Quando incontra una riga eccessivamente lunga, individua l’ultimo spazio che precede la posizione 86 e inserisce là il segno “\n” (newline ‘a capo’). Se la riga dopo “\n” supera ancora 86 caratteri, ripete l’operazione, e via di seguito. O meglio: sebbene si tratti di un classico compito ricorsivo, a causa delle nostre limitate capacità di programmazione non siamo riusciti a trattarlo come tale e il programma esegue invece l’operazione fino a quattro volte. Questo procedimento nel nostro corpus permette di sistemare quasi tutti i casi. Quando ci sono monologhi molto lunghi e permane una riga troppo lunga, la riga deve essere divisa manualmente. Speriamo migliorare questo script con l’aiuto di un/a professionista, ma nel frattempo serve anche nella sua forma attuale! – L’ultima operazione che lo script esegue è, come in quello precedente, il salvataggio del documento con un nome nuovo, appendendo “concat” al nome della versione precedente.
L’ultimo programma del pacchetto si applica in fase di revisione finale. Innanzitutto, identifica e segnala all’utente etichette di parlanti ripetute in righe adiacenti che si sono venute a creare dopo gli interventi manuali sui discorsi in sovrapposizione e che sono passate inosservate. In secondo luogo, riporta tutte le righe dove figura sia una marca di timecode "((TC))", sia una parentesi quadra, aggiungendo due righe precedenti e due successive. Infatti in quei casi la formattazione automatica dei discorsi sovrapposti fatta da ELAN è stata disturbata dall'inserimento di sei caratteri aggiuntivi e ne risultano errori di allineamento che devono essere corretti a mano. Durante il lavoro manuale sui passi sovrapposti, si nota la maggior parte di questi errori, ma è probabile che alcuni sfuggano a chi rivede le trascrizioni. L'elenco dei passi presentato dal programma facilita l'identificazione di quegli errori. In terzo luogo, il programma trova tutte le istanze del segno “-->”. Questo segno fa parte della trascrizione di eventi acustici nell’ambiente dell’interazione, che nel corpus TIGR sono stati annotati su un tier ELAN separato chiamato ambient_noises. Quando il fenomeno acustico ha una certa durata (come il rumore di una macchina da caffè, di una sirena, di acqua che corre), “-->” contribuisce a indicare i suoi confini temporali. Abbiamo notato un certo tasso di errori nella trascrizione di questi fenomeni, sia nel documento originale ELAN, sia nella versione testo, e il programma mira a facilitare la revisione.
Il presente contributo termina la serie che abbiamo dedicato al tema delle trascrizioni in formato testo. Nelle settimane a venire torneremo indietro nel tempo per parlare delle fasi iniziali della collezione del corpus TIGR, che sono state decisive a molti riguardi e hanno anche presentato sfide inaspettate, in rapporto soprattutto con la pandemia da Covid-19.
Johanna Miecznikowski
