
Exploring LaRS @ SWISSUbase
ShareTIGR
18 April 2024
Having discussed the type of data constituting the TIGR corpus last week, it is now time to take a closer look at the platform on which we will store the data, i.e., the Language Repository of Switzerland (LaRS) at SWISSUbase. While you can find some general elaborations on LaRS’ features here, I would like to use this article to dive deeper into the organisational structure of the repository: What are the possibilities and limitations a linguist encounters when storing their data on LaRS? In what units can (or must) the data be organised? And at which levels can metadata be added and used for the findability of the data on the repository?
Let us start at the very beginning… If you want to store your data on SWISSUbase, which is the repository system of LaRS, you need to login with your edu-ID and create a “study”. Even before you give the study a name, you must select a “scientific domain” for it, either "Linguistics" or "Social sciences". As soon as you have made that choice, your study is automatically assigned to either LaRS or FORS, which will curate your data according to their metadata scheme and hence define the design and extent of your study description. Due to this defining setup, it is not possible to change the scientific domain later in the process.
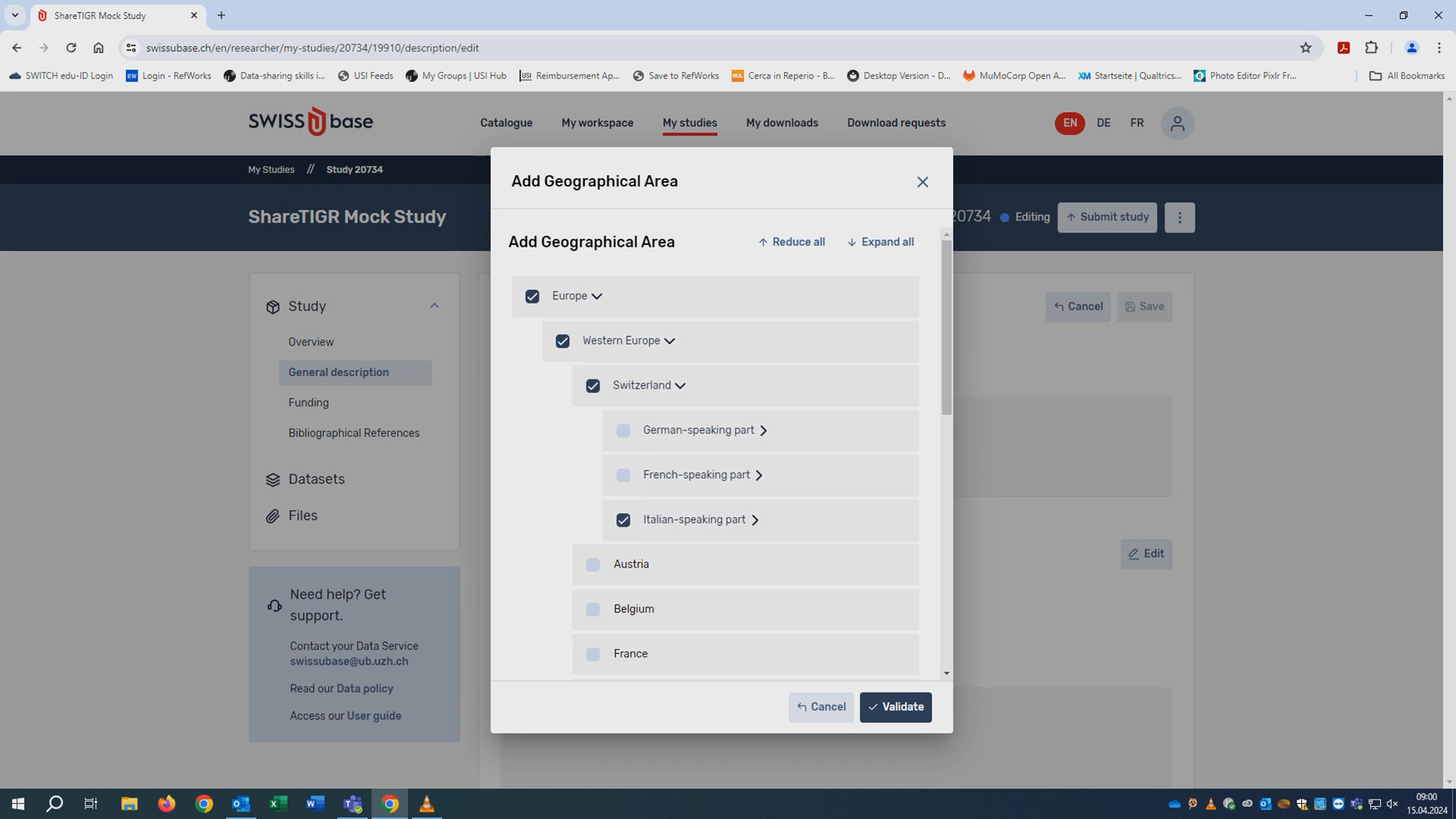
After the basic settings are done, you can start to describe your study by providing information such as its name and discipline(s), the time and geographical area of its origin, its funding, and bibliographical references. It is also possible to indicate a language (EN, DE, FR, IT) but beware, this language does not refer to the content of the data but to the language in which the study is described on the platform. We will get back to this point in a moment.
Once you have completed the study description you can proceed to upload the data. LaRS has a hierarchical structure that subdivides a “study” into one or more “datasets” and a dataset into one or more “files”. A file can either be a “Single Data File”, a “Collection of Files” (a zip folder) or a “Documentation” file like a codebook or annotation description. The number of datasets per study and the number of files per dataset are, in theory, unlimited. Each hierarchical level has its own metadata. The metadata categories at study level are the same for linguistic and social science projects, as this ensures the searchability and findability of all studies in the SWISSUbase catalogue. The metadata at dataset and file level, however, differ between the two scientific domains. On the dataset level of a linguistic record, general information such as a title (e.g., “Speech event 18”), the “resource type” (e.g., corpus, language description, computational resource) or keywords can be provided. Additionally, restricted user contracts and usage licenses can be assigned to each dataset. Indeed, the dataset is the unit a user will be able to download, while it is not possible to download either an entire study or a single file. The assignment of user contracts and licenses at dataset level enables a data depositor to upload records with varying levels of confidentiality or applicable data protection laws. The most fine-grained metadata can be added on file level. LaRS has developed an extensive metadata scheme specifically tailored to linguistic studies (see here) which even can be expanded in case categories are missing. It features the categories “Language”, “Annotation”, “Text”, “Audio”, “Video”, “Image”, and “Tools” which not only enables the description of multimodal language data, but also the description of their processing software and tools.
Let us now leave the perspective of a data depositor and take the role of a user. SWISSUbase has a catalogue with currently 12.242 studies (April 18th, 2024) that offers some basic search and filter options. You can filter the catalogue by data access, scientific domain, discipline, study description language, geographical area, and funding. As mentioned above, these are the metadata categories of the study level to ensure that both linguistic and social science records can be found. However, these search filters are fairly limited and have several disadvantages, especially with regard to the category “language”. It is only possible to filter for the language used to describe a study, but not for the language studied. Of course, there may be cases in which the two languages coincide, but if they do not, and if neither the study title nor the geographical area includes the information, the user will most probably click through the study until they reach the file level. There, hopefully for the user the depositor added this metadata, but language is in fact not a mandatory field. To obtain information about the object language(s), an alternative possibility is to filter the studies by disciplines, as SWISSUbase includes three disciplinary categories that name languages: “Romance languages and literature”, “German and English languages and literatures”, and “Other languages and literature”. Due to how the disciplinary metadata are organised in the repository, a resource in linguistics will not necessarily be classified in these terms, however; data depositors may have chosen superordinate categories such as "Linguistics and literature, philosophy" instead of a more specific category that names a language family. In addition, the label “German and English languages and literatures” is not utterly clear: Does it refer to the family of Germanic languages, giving special visibility to English, or does it refer to a more restricted set of languages? Hard to tell.
It is worth noticing that SWISSUbase does not have many mandatory fields when creating a study. As a result, some studies have data but lack metadata (beyond the few mandatory categories) - or the other way around. When you filter the 12.242 studies on SWISSUbase by entries with a dataset, the number of available studies falls to 526, which shows that quite frequently researchers create a study without uploading data. This line of action may seem counterintuitive at first glance. However, SWISSUbase provides the field “data availability” where depositors can indicate whether they plan to deposit their data in SWISSUbase or on another platform; if they deposit their data on another platform, they are asked to provide further information, e.g., a website. This field suggests that SWISSUbase is not designed solely to store data and make them directly accessible (the A of the FAIR principles), but also to simply increase the data's findability (the F of FAIR), since it is a searchable platform that provides DOIs for each dataset. For a more detailed explanation of the FAIR principles for scientific data management and stewardship, see Wilkinson et al. (2016).
Lastly, I want to make a few remarks about the linguistic studies currently available in the catalogue. When you filter by discipline, there are 172 linguistic studies; when filtering by scientific domain, there are 24. This means there are roughly 150 studies with linguistic content that are not curated by LaRS (but by FORS) and that do not use (or need) the discipline specific metadata scheme. Only 6 of these studies have at least one dataset, but all of them are restricted. On the other hand, 23 out of the 24 studies curated by LaRS have at least one dataset. 13 of them are open access, 9 are restricted and one is mixed with restricted and open datasets in one study. These observations suggest that, compared to other parts of SWISSUbase, LaRS is more systematically used to actually make data accessible.
Now that we have gained a general understanding of the data structure on SWISSUbase, we can take a closer look at the future organisation of the TIGR corpus on the repository. Next week, we will therefore address how the TIGR corpus can be transferred into the study design of LaRS @ SWISSUbase, how we intend to structure the corpus’ speech events into datasets and which record versions might be relevant for future usage scenarios.
Nina Profazi
References
SWISSUbase. Catalogue. https://www.swissubase.ch/en/catalogue/search?q=&p=0&ps=10&sn=ref-number&sd=desc (retrieved April 18, 2024)
SWISSUbase (2023). Metadata Guide for Linguistics Data. Metadata documentation. Version 1.1. https://resources.swissubase.ch/wp-content/uploads/2023/12/Linguistics_Metadata-Guide_en.pdf
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J. W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Waagmeester, A., Wittenburg, P., Wols tencroft, K., ... Velterop, J. (2016). The FAIR guiding principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18
